
3月30日,阿里正式发布千问新一代全模态大模型Qwen3.5-Omni。该模型在音视频理解、识别、交互等215项任务中取得SOTA成绩,核心指标超越Gemini-3.1 Pro,跻身全球顶尖全模态大模型行列。
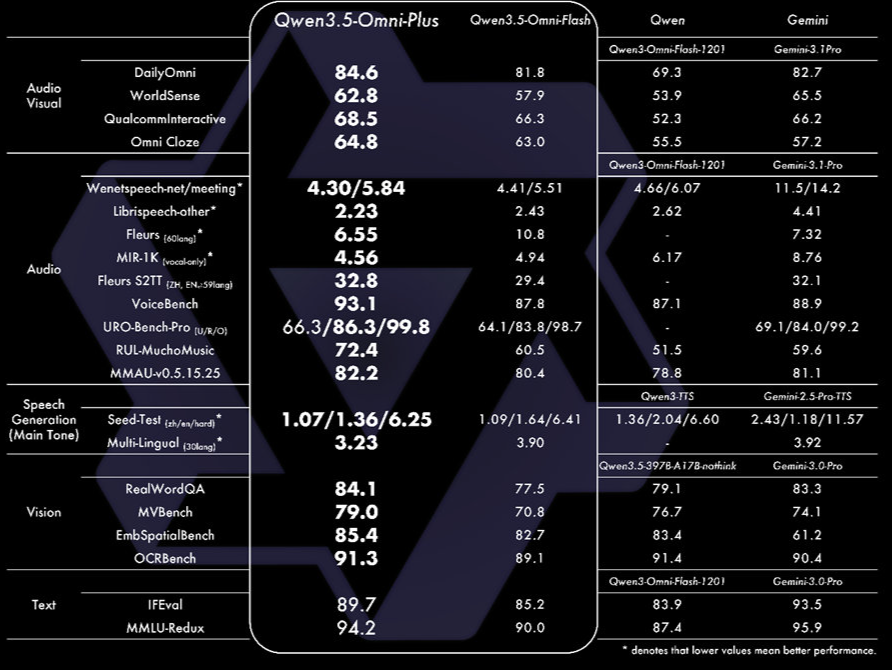
Qwen3.5-Omni采用Hybrid-Attention MoE架构,基于海量文本、视觉及超1亿小时音视频数据完成原生多模态预训练,支持文本、图片、音频、音视频全模态输入输出。其音视频理解能力可实现细粒度结构化描述,能精准识别113种语言及方言,还自然涌现出音视频Vibe Coding能力——用户对着镜头口述需求,即可生成可运行的代码。
实时交互体验也迎来升级,模型支持语义打断、音色克隆、语音控制等功能,可像真人一样灵活调节语速、情绪,还能自主调用WebSearch和工具完成复杂任务。Plus版本支持256K超长上下文,可处理超10小时音频或1小时视频。
目前,阿里云百炼已上线Plus、Flash、Light三种API规格,覆盖短视频、游戏、自媒体等场景。普通用户可前往Qwen Chat免费体验,开发者调用成本每百万Tokens不到0.8元,仅为Gemini-3.1 Pro的十分之一。
(来源:驱动中国)
相关推荐
-
阿里发布全球首个企业级Agent平台“悟空”
3月17日,阿里巴巴发布全球首个企业级AI原生工作平台——“悟空”,让每个团队、每家公司,都能拥有一支24h工作的“龙虾军团”。悟空是一款独立应用,即日起开启邀测,也将直接内置到超2000万企业组织的钉钉之中。
-
千问“30亿免单”引发全民抢奶茶 火爆致App崩溃
2026年2月6日,阿里旗下AI助手“千问App”正式启动“春节30亿大免单”第一波活动,用户更新至最新版本后,即可领取25元无门槛免单卡,用于免费点奶茶、买年货或点外卖。活动上线仅数小时,便因参与人数激增导致系统超载,大量用户反馈App出现“崩了”“无法下单”等故障,相关话题迅速登上微博热搜第四位。
-
阿里巴巴携手国际奥委会发布奥运史上首个官方大模型,开启史上最智能的一届奥运会
2026年2月5日,在米兰科尔蒂纳冬奥会即将开幕之际,国际奥委会与全球数字科技企业阿里巴巴集团在米兰阿里云智能体验中心联合举办活动,共同宣布奥运史上首个由人工智能大模型驱动的“奥运会官方大模型”正式落地。这一里程碑标志着人工智能技术首次全面、大规模融入奥运赛事运营、内容制作与全球互动体验,米兰冬奥会因此将成为“史上最智能的一届奥运会”。
-
“碰一碰”唤醒AI旅行搭子,千问APP走进酒店客房
近日,阿里千问APP落地酒店场景,率先在多家合作酒店部署基于NFC技术的“碰一碰”功能。住客只需用手机轻碰千问感应贴纸,即可一键唤醒千问APP,获得基于地理位置的景点导览、特色餐饮、交通路线等个性化内容,并同步领取淘宝闪购优惠券等权益。该功能依托客房内已有的天猫精灵智能音箱硬件,首批落地杭州、广州、昆明等热门旅游城市,计划春节前覆盖上万间客房。
-
淘宝闪购盒马全接入 千问App投入30亿启动“春节请客计划”
2026年2月2日,阿里巴巴旗下AI超级应用千问App宣布启动“春节请客计划”。该计划号称高达30亿元的全民福利行动,将于2月6日全面上线。该计划将联合淘宝闪购、飞猪、盒马、大麦、天猫超市、支付宝等阿里生态核心业务,以“免单”形式邀请全国用户在春节期间畅享吃喝玩乐,旨在加速普及AI驱动的全新生活方式。
-
昨夜今晨:苹果2026财年一季度营收创新高 豆包AI手机新产品预计二季度问世
2026年1月30日 星期五 驱动中国昨夜今晨 昨夜今晨:苹果2026财年一季度营收创新高 豆包AI手机新产品预计二季度问世
-
阿里平头哥真武810E芯片发布 性能已看齐英伟达H20
阿里巴巴旗下平头哥半导体正式在官网宣布其最新一代高端AI芯片“真武810E”,标志着由通义实验室、阿里云与平头哥共同构成的阿里巴巴AI战略核心“通云哥”黄金三角全面成型。这款此前因亮相央视《新闻联播》而备受瞩目的自研PPU(并行处理单元),不仅实现了从架构到软件栈的全链路自主研发,更在关键性能指标上比肩英伟达H20,成为国产AI芯片迈向高端算力自主可控的重要里程碑。
)





)


